controlnet 使用
controlnet 模型
controlnet 模型命名规范
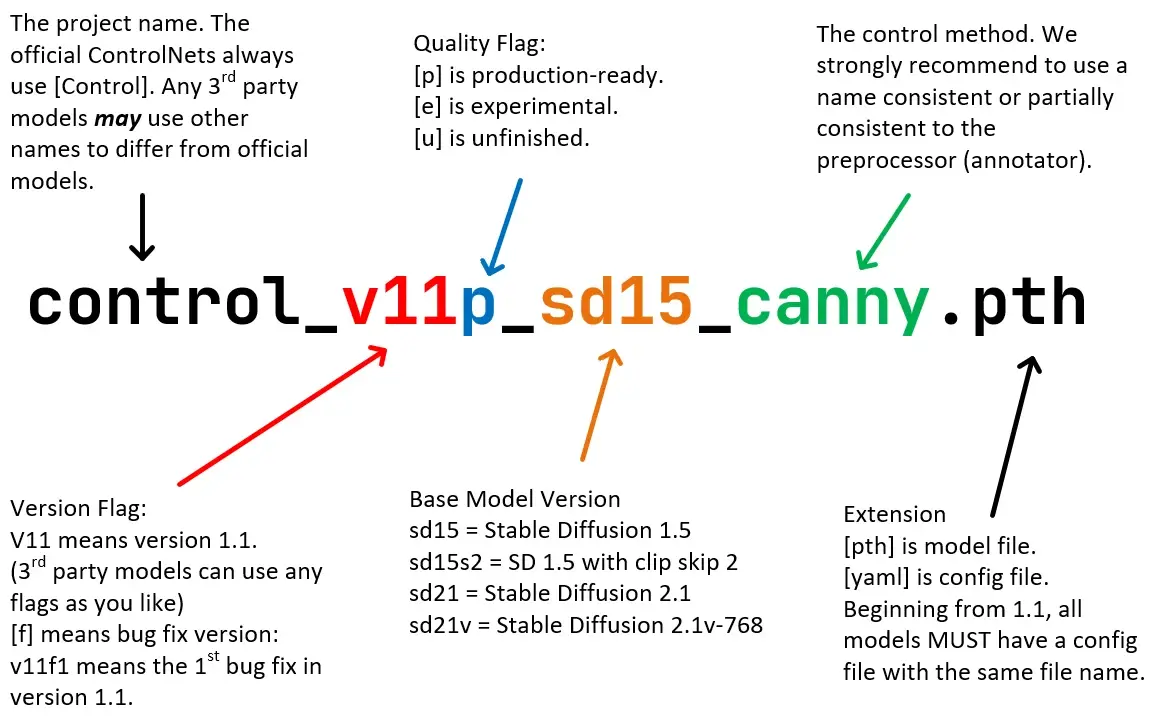
项目名称:control
官方总是以control为项目名,其他第三方会用自己的名称表示,例如coadapter、ti2adapter等版本标记:v11
该controlnet版本号,v11意味着1.1版本质量标记:p
标识:[p]:正式产品;[e]:测试版; [u]:未完成版; [f]修复版;大模型版本:sd15
将stable diffusion 1.5 版作为基础模型进行训练模型控制方法:canny
该模型功能,比如 canny 是边缘检测模型文件类型:pth
文件名后缀,有pth、safetensors等,一般还有 yaml 配置文件,从 1.1 开始,所有文件都需要有一个同名字的配置文件。
插件使用
controlnet 更新跟安装这里就不讲解了,使用到的模型可以去 huggingface上下载(1.1后需要下载对应的模型文件 .pth 以及对应的 yaml 配置文件,下载完毕后,放在目录
sd-webui-aki-v4\models\ControlNet\下载好的模型如下图:
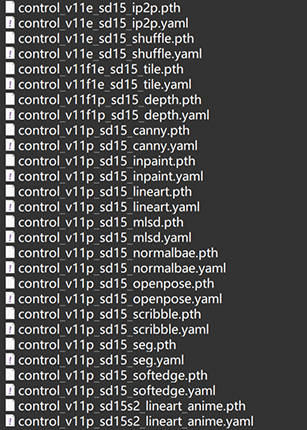
controlnet 1.1 官方给了 14 个模型,11 个正式版,3 个实验性模型,预处理器有 30 多个。
安装了插件后,打开文生图,或者图生图,就能找到 ControlNet 的操作界面:
- 启用:点击可以启用 ControlNet
- 低显存模式:开启显存优化,8G 以下显卡的福音
- 完美像素模式:由 ControlNet 自己决定预处理的解析度
- 运行预览:开启后会出现预览窗口
启用 controlnet,并且选择想使用的预处理器跟模型后,再点击生成图片,即可看到应用 controlnet 后的生成效果了。
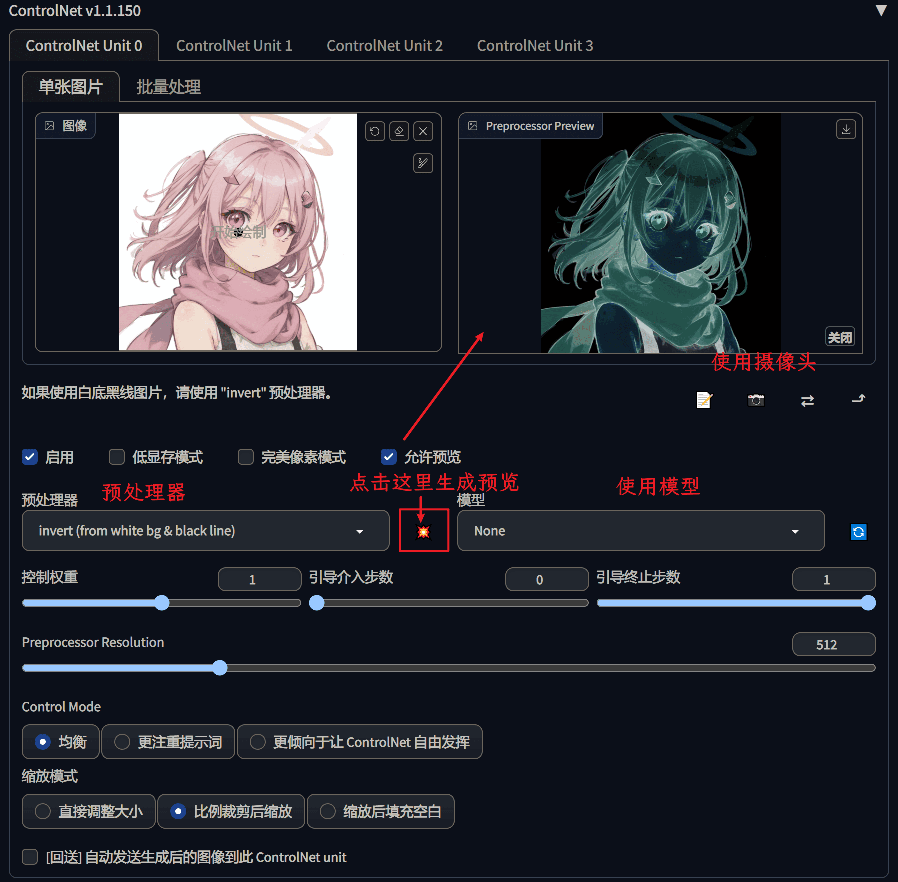
选择好对应的模型跟匹配的预处理器后,点击预览才可以正确显示预处理结果,如果发现效果不对,请验证下模型跟预处理器是否匹配。如果没有对应的模型或者预处理器,则选择 none 即可。
预处理器跟模型是有对应关系的,不能乱用,下面的表格是官方提供的模型跟预处理器之间的关系:
| 模型名 | 用途 | 预处理器 | 备注 |
|---|---|---|---|
| 白底黑线反色 | invert | ||
| 面部控制 | mediapipi_face | ||
| 参考来源图片 | refrence_only | 仅参考输入图 | |
| refrence_adain | 输入图+自适应范例 | ||
| refrence_adain+attn | 输入图+自适应范例+attention | ||
| 1.control_v11p_sd15_canny | 边缘检测 | canny | |
| 2.control_v11f1p_sd15_depth | 深度检测 | depth_leres | |
| depth_midas | |||
| depth_zoe | |||
| 3.control_v11p_sd15s2_lineart_anime | 动漫线稿控制 | lineart_anime | |
| lineart_anime_denoise | 带去噪 | ||
| 4.control_v11p_sd15_lineart | 线稿控制 | lineart_coarse | 粗略线提取 |
| lineart_realistic | 写实线提取 | ||
| lineart_standard | 标准 | ||
| 5.control_v11p_sd15_mlsd | 直线检测 | mlsd | 直线检查,适用于建筑,室内装修图 |
| 6.control_v11p_sd15_normalbae | 法线贴图 | normal_bae | |
| normal_midas | |||
| 7.control_v11p_sd15_openpose | 姿态控制 | openPose | 仅姿态 |
| openpose_face | 姿态 + 脸部 | ||
| openpose_faceonly | 仅脸部 | ||
| openpose_full | 姿态、手部及脸部 | ||
| openpose_hand | 姿态 + 手部 | ||
| 8.control_v11p_sd15_scribble | 涂鸦 | scribble_hed | 合成 |
| scribble_pidinet | 手绘 | ||
| scribble_xdog | 强化边缘 | ||
| 9.control_v11p_sd15_seg | 语义分割 | seg_ofade20k | |
| seg_ofcoco | |||
| seg_ufade20k | |||
| 10.control_v11e_sd15_shuffle | 风格洗牌转移 | shuffle | |
| 11.control_v11p_sd15_softedge | 软边缘 | softedge_hed | |
| softedge_hedsafe | |||
| softedge_pidinet | |||
| softedge_pidisafe | |||
| 12.control_v11e_sd15_ip2p | 图生图 | 预处理器选 None | |
| 13.control_v11f1e_sd15_tile | 分块采样 | ||
| 14.control_v11p_sd15_inpaint | controlnet自带的局部重绘 | inpaint_global_harmonious |
各个模型的对比
invert(白底黑线反色)
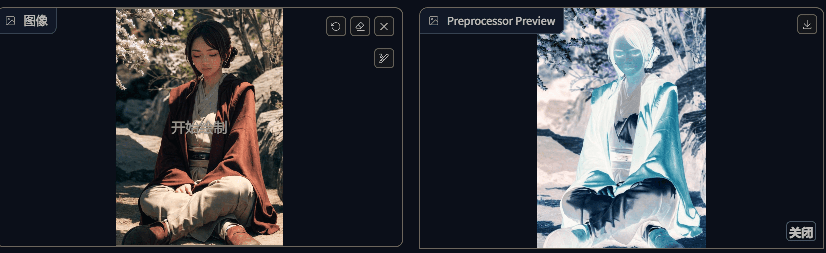
没有对应的模型,应该是配合其他预处理器一起使用。
Pix2Pix(图生图)
这是 ControlNet 提供的图生图,通过输入指令,来生成新图的模型,使用的提示词,原图中的部分要素还在,然后季节改变成提示词中给定的了
make it winter,
shuffer(风格洗牌)
不输入任何提示词的情况下:

输入提示词的情况:
hongkong
depth(深度检测)
使用深度预处理器,会同时生成一张深度图,然后会根据这张深度图来控制最终的生成的效果图。下面是几种深度预处理器的对比,随机种子固定为:123456
depth_leres

depth_midas

depth_zoe

canny(边缘检测)
canny 是先生成原图的描边线稿,然后通过线稿来控制最终生成的图片。

下面是人物效果

lineart(线稿控制)
lineart 有三个处理器:
- lineart_coarse(粗略线提取)

- lineart_realistic(写实线提取)

- lineart_standard(标准)

lineart_anim(动漫线稿)
- lineart_anime

- lineart_anime_denoise(带去噪)

去噪后,线稿约束小了,最终生成的效果也天马行空了。
mlsd(直线检测)
这个模型用来检测直线边缘,对曲线的检查效果很差,适合做建筑,或者室内装修的生成。

当然用上面的线框图效果也可以(lineart_coarse)

mediapipe_face(面部控制)
这个没有模型,也是配合其他预处理器一起使用的。
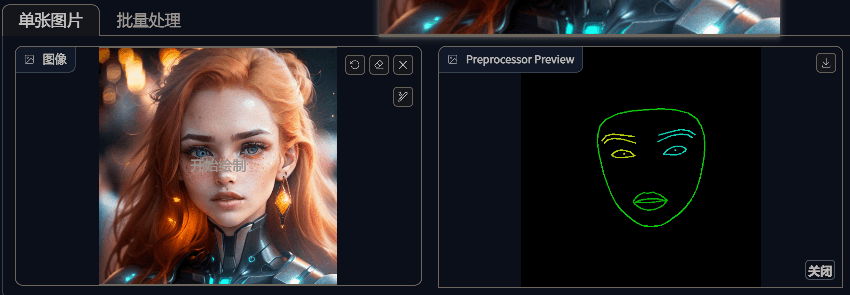
normal(法线贴图)
normal 处理器会对图片进行预处理,生成法线贴图,然后使用法线贴图控制最终生成的图片。
- normal_base

- normal_midas

openpose(姿态控制)
下面的测试,使用了同一个随机种子 1391169082,模型是 breakdro,关键词都留空了
- openpose(仅姿态)
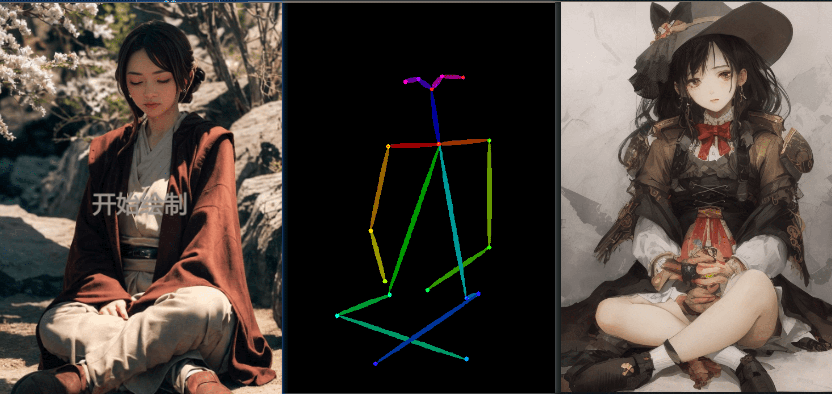
姿态图也可以自己通过第三方软件制作,blender 等工具
- openpose_face(姿态 + 面部)
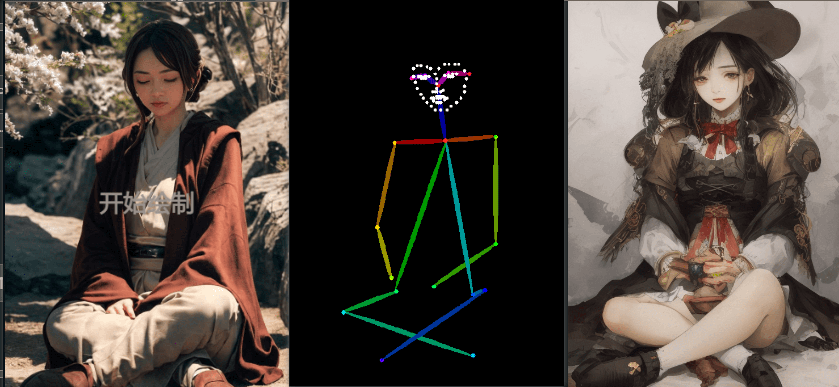
增加脸部后,出现了脸部的控制点
openpose_face_only(仅脸部)

画风不一致,是因为只控制了脸部,AI 开始天马行空,不得已增加了关键词 nsfw
openpose_full(姿态、手部及脸部)
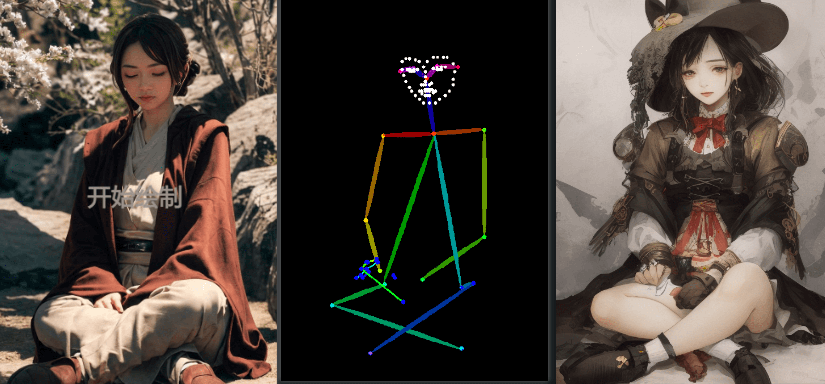
注意手部被识别到了,姿态图出现手部
openpose_hand(姿态 + 手部)
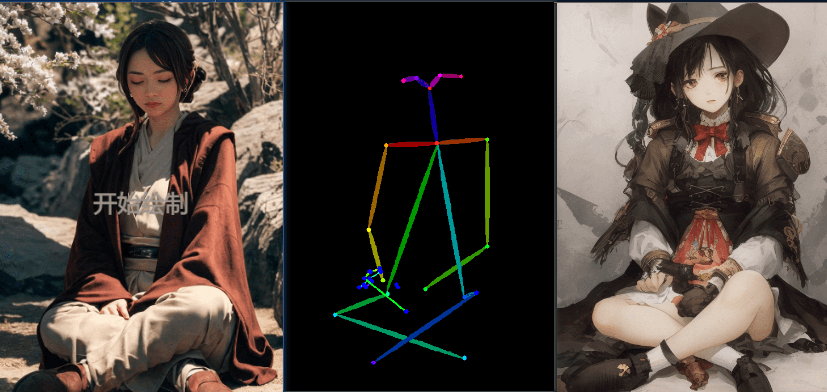
scribble(涂鸦)
scribble_hed(合成)

scribble_pidinet(手绘)

scribble_xdog(强化边缘)

强化边缘后,细节增多。
seg(语义分割)
语义分割是将标签或类别与图片的每个像素关联的一种深度学习算法。把画面中的内容按照物体分开,并且将同一类的像素归到一个类别,最终生成一张色块图。
- seg_ofade20k

- seg_ofcoco

- seg_ufade20k

softedge(软边缘)
- softedge_hed

- softedge_hedsafe

- softedge_pidinet:

对比 hed 算法,缺失了一些细节,注意看面部眼睛。
- softedge_pidinetsafe

inpaint
一般在图生图中使用,用于局部修复
refrence
可以实现 LoRA 模型的效果,参考输入图片,生成效果图:
- reference_only
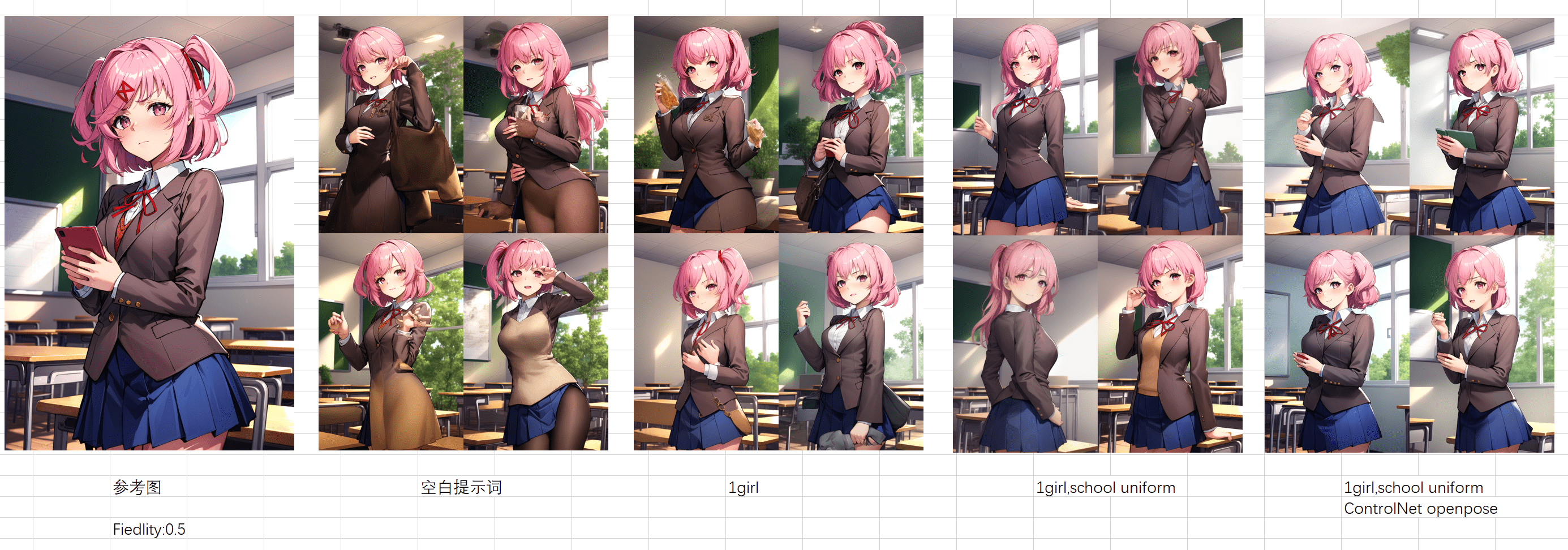
refrence 使用时,需要配合提示词以及参考图对应的风格的模型,如果只使用参考图,最终生成的画面可能会崩掉,官方推荐使用 reference_only + style
- reference_adain

- reference_adain+attn

tile
这个模型有两个用途:
- 忽略图片中的一些细节,并且会产生新的细节
- 如果局部快中语义合全局提示词不匹配,会忽略全局提示词,并根据局部上下文引导扩散
高清修复
官方链接中给了一张 64*64 的小狗图,我们可以用 tile 模型对这个图片放大,并且增加丰富的细节,大小可以自己设置(这里设置成 512 * 512)。
a dog, on grass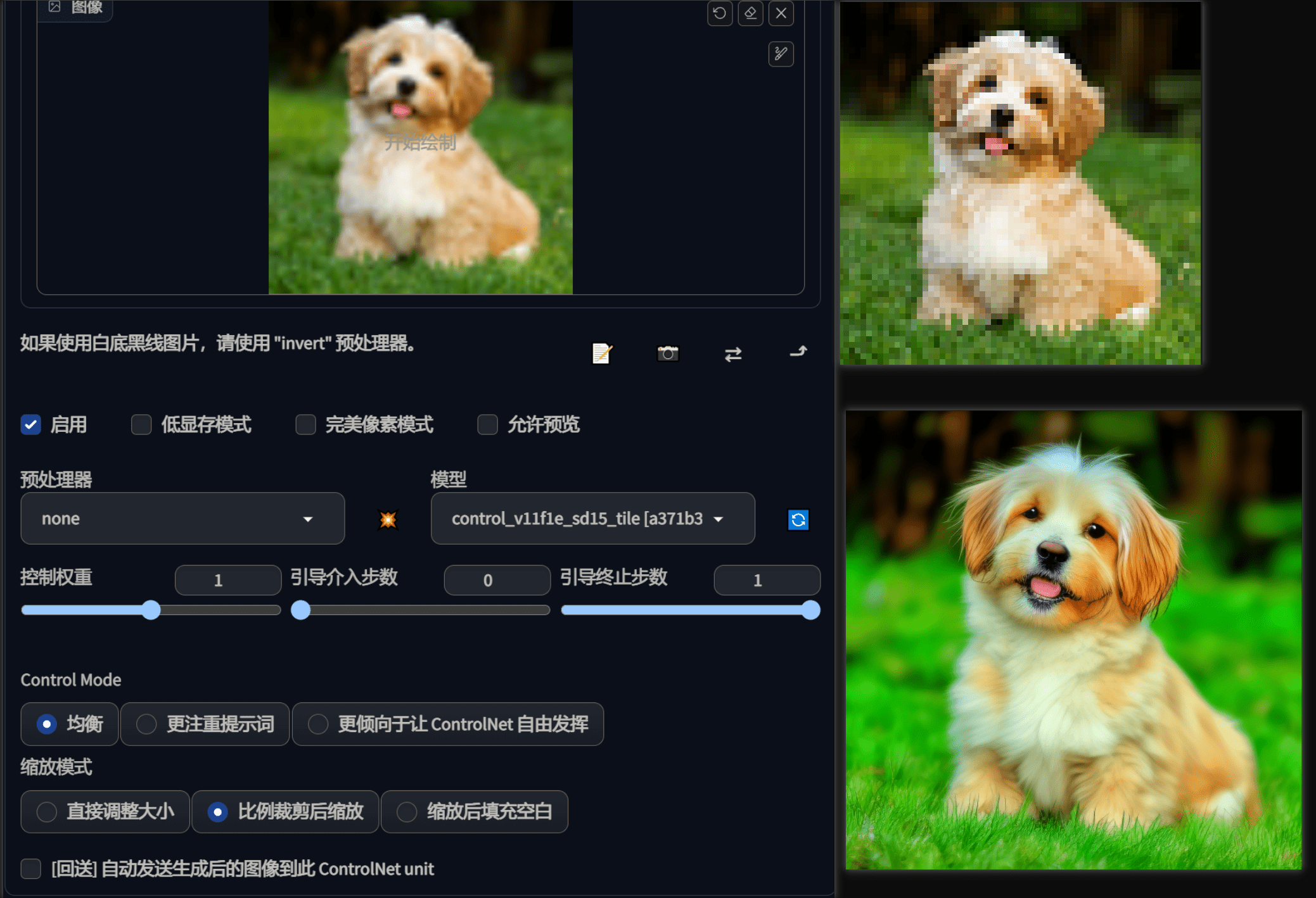
预处理器这里可以选 none,如果选了 tile_resample,可以对输入的图片进行缩小后再作为参考输入,可以 设置缩小的比例。
修复一些不能直接放大的图
下面这张图图片尺寸比较大,但是细节基本丢失,这个图片就不能使用常规的放大算法(需要补充大量细节),就可以利用 tile 的特性,让模型自动忽略一些错误的细节,然后生成我们想要的效果。
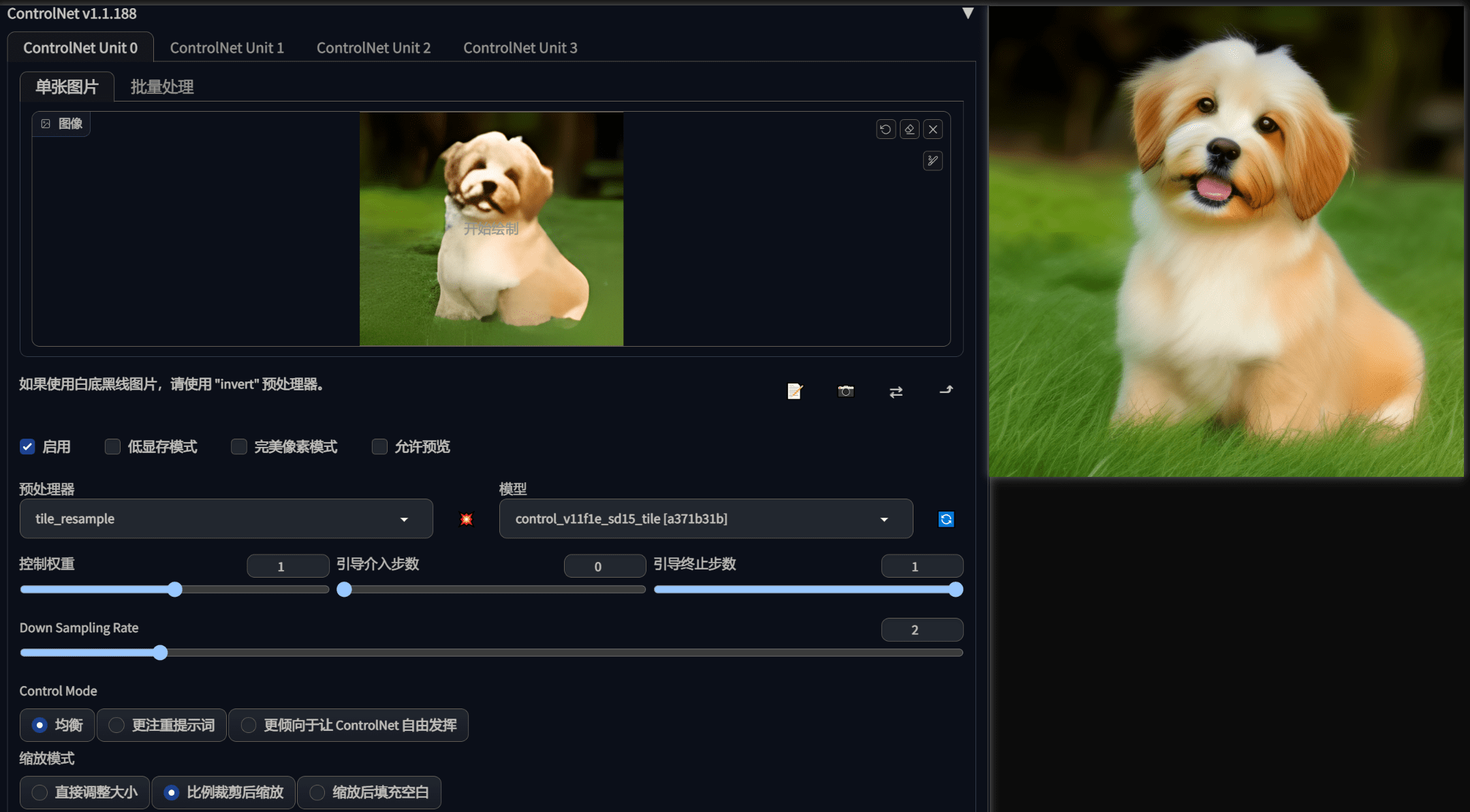
这里我们使用了预处理器,因为这张图的大小比较大,因此我们可以使用预处理区现将图片缩小。
有了这个功能后,我们就可以自己使用一些简略图,让 AI 给我们画出不错的创意了
a beautiful house, stone steps path
配合 SD scale 放大算法
在图生图中默认有 SD scale 算法(打开脚本下拉,就能看到),这两个算法在放大时,都做了显存优化,会按照最终生成的图片大小进行分块,然后逐块生成,最后再将这些合并成大图。
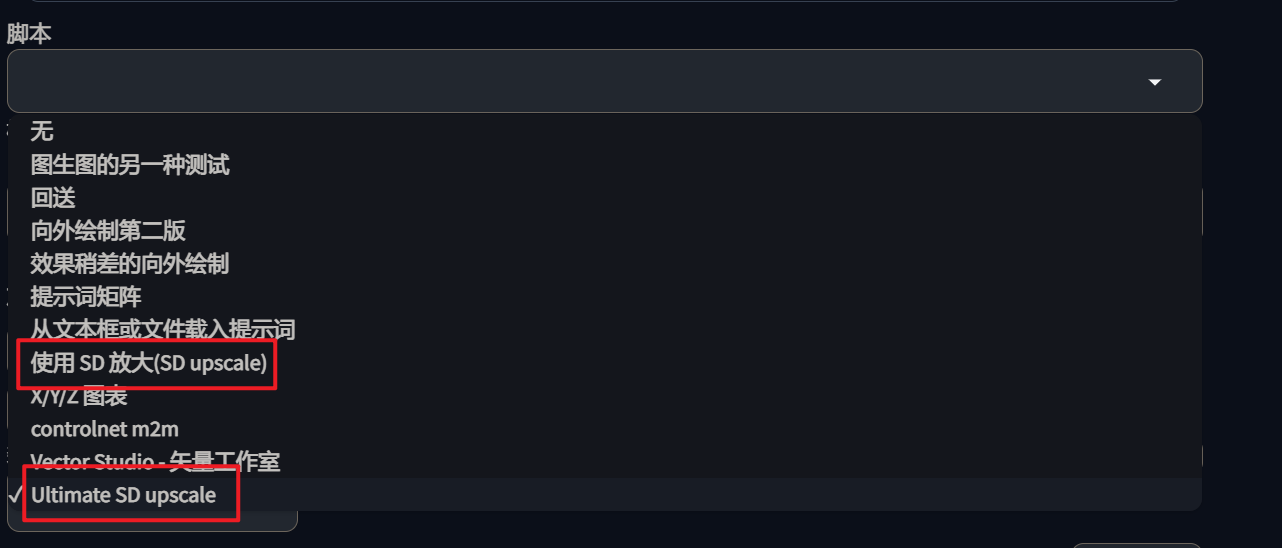
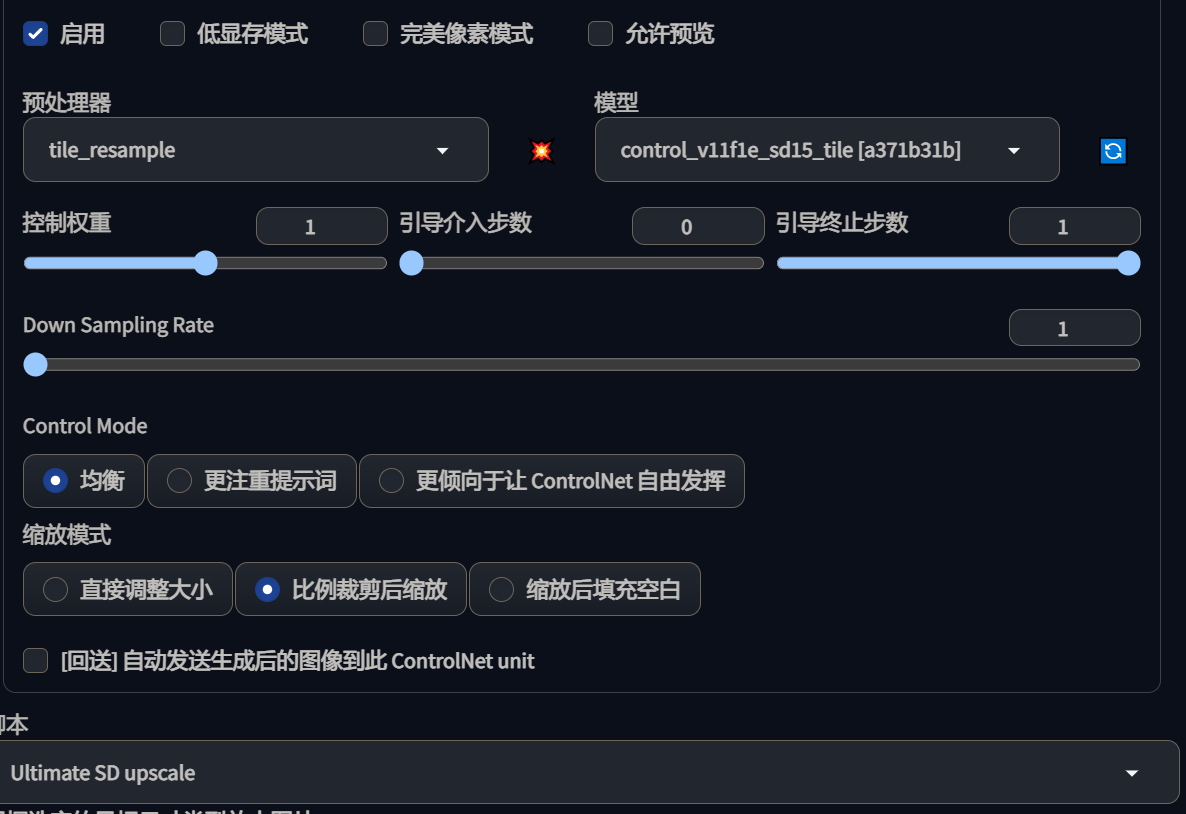
直接使用的话,每块都会受到提示词的影响,最终导致生成的结果混乱,因此可以配合 ControlNet 的 tile 模型,控制最终生成的结果。
controlnet 参数,Ultimate SD upscale 参数保持默认
下面是将图片从 568 * 561 放大 3 倍后的效果,放大后细节做了补充,效果很惊艳。

- SD 图生图自带两个放大算法 “Ultimate SD upscale” 跟 “SD upscale”,两个是完全不同的放大算法。
- “Ultimate SD upscale” 是 1.1 版本开始支持的
- “SD upscale” 是 1.1.117 版本开始支持,使用时,ControlNet 里的图片要置空,因为不好维护,官方推荐使用 “Ultimate SD upscale”
- 普遍使用的放大算法还是 Tiled VAE/Diffusion 扩展,但是官方说 ControlNet 1.1 兼容大部分的 tile-based 扩展,使用 Tile VAE 细节没有使用 ControlNet + SD 放大算法的惊艳
这个放大算法也不是完美无瑕,测试中也会发现一些问题(放大倍数很高的时候 4倍):
- 会有多出来的眼睛
- 图片中有景深时,每个块景深可能不一样,导致整体上景深是错乱的。
- 块之间会有明显的接缝痕迹。

配合使用
可以同时配合多个 ControlNet 效果一起使用:

预处理器推荐使用场景
- 1.人物/肖像:canny(棱角分明)、lineart(线条分明,处理细致)、scribble(自由发挥度比较高)、softedge(保留更多细节)
- 2.动作控制:openpose
- 3.动漫:lineart-anime(处理细致)
- 4.建筑:depth(深度信息比较多的图)、mlsd(出室内效果图)、normal(可以做游戏建模)
- 5.修图:inpaint(主要用于肖像)
- 复杂的图:seg(处理很优秀)
参考
3.ControlNet for Stable Diffusion WebUI